 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeD4PM: A Dual-branch Driven Denoising Diffusion Probabilistic Model with Joint Posterior Diffusion Sampling for EEG Artifacts Removal
Sep 17, 2025Artifact removal is critical for accurate analysis and interpretation of Electroencephalogram (EEG) signals. Traditional methods perform poorly with strong artifact-EEG correlations or single-channel data. Recent advances in diffusion-based generative models have demonstrated strong potential for EEG denoising, notably improving fine-grained noise suppression and reducing over-smoothing. However, existing methods face two main limitations: lack of temporal modeling limits interpretability and the use of single-artifact training paradigms ignore inter-artifact differences. To address these issues, we propose D4PM, a dual-branch driven denoising diffusion probabilistic model that unifies multi-type artifact removal. We introduce a dual-branch conditional diffusion architecture to implicitly model the data distribution of clean EEG and artifacts. A joint posterior sampling strategy is further designed to collaboratively integrate complementary priors for high-fidelity EEG reconstruction. Extensive experiments on two public datasets show that D4PM delivers superior denoising. It achieves new state-of-the-art performance in EOG artifact removal, outperforming all publicly available baselines. The code is available at https://github.com/flysnow1024/D4PM.
Quaternion Multi-focus Color Image Fusion
May 05, 2025Multi-focus color image fusion refers to integrating multiple partially focused color images to create a single all-in-focus color image. However, existing methods struggle with complex real-world scenarios due to limitations in handling color information and intricate textures. To address these challenges, this paper proposes a quaternion multi-focus color image fusion framework to perform high-quality color image fusion completely in the quaternion domain. This framework introduces 1) a quaternion sparse decomposition model to jointly learn fine-scale image details and structure information of color images in an iterative fashion for high-precision focus detection, 2) a quaternion base-detail fusion strategy to individually fuse base-scale and detail-scale results across multiple color images for preserving structure and detail information, and 3) a quaternion structural similarity refinement strategy to adaptively select optimal patches from initial fusion results and obtain the final fused result for preserving fine details and ensuring spatially consistent outputs. Extensive experiments demonstrate that the proposed framework outperforms state-of-the-art methods.
Quaternion Infrared Visible Image Fusion
May 05, 2025Visible images provide rich details and color information only under well-lighted conditions while infrared images effectively highlight thermal targets under challenging conditions such as low visibility and adverse weather. Infrared-visible image fusion aims to integrate complementary information from infrared and visible images to generate a high-quality fused image. Existing methods exhibit critical limitations such as neglecting color structure information in visible images and performance degradation when processing low-quality color-visible inputs. To address these issues, we propose a quaternion infrared-visible image fusion (QIVIF) framework to generate high-quality fused images completely in the quaternion domain. QIVIF proposes a quaternion low-visibility feature learning model to adaptively extract salient thermal targets and fine-grained texture details from input infrared and visible images respectively under diverse degraded conditions. QIVIF then develops a quaternion adaptive unsharp masking method to adaptively improve high-frequency feature enhancement with balanced illumination. QIVIF further proposes a quaternion hierarchical Bayesian fusion model to integrate infrared saliency and enhanced visible details to obtain high-quality fused images. Extensive experiments across diverse datasets demonstrate that our QIVIF surpasses state-of-the-art methods under challenging low-visibility conditions.
Rethinking Diffusion-Based Image Generators for Fundus Fluorescein Angiography Synthesis on Limited Data
Dec 17, 2024Fundus imaging is a critical tool in ophthalmology, with different imaging modalities offering unique advantages. For instance, fundus fluorescein angiography (FFA) can accurately identify eye diseases. However, traditional invasive FFA involves the injection of sodium fluorescein, which can cause discomfort and risks. Generating corresponding FFA images from non-invasive fundus images holds significant practical value but also presents challenges. First, limited datasets constrain the performance and effectiveness of models. Second, previous studies have primarily focused on generating FFA for single diseases or single modalities, often resulting in poor performance for patients with various ophthalmic conditions. To address these issues, we propose a novel latent diffusion model-based framework, Diffusion, which introduces a fine-tuning protocol to overcome the challenge of limited medical data and unleash the generative capabilities of diffusion models. Furthermore, we designed a new approach to tackle the challenges of generating across different modalities and disease types. On limited datasets, our framework achieves state-of-the-art results compared to existing methods, offering significant potential to enhance ophthalmic diagnostics and patient care. Our code will be released soon to support further research in this field.
Multi-rater Prism: Learning self-calibrated medical image segmentation from multiple raters
Dec 01, 2022



In medical image segmentation, it is often necessary to collect opinions from multiple experts to make the final decision. This clinical routine helps to mitigate individual bias. But when data is multiply annotated, standard deep learning models are often not applicable. In this paper, we propose a novel neural network framework, called Multi-Rater Prism (MrPrism) to learn the medical image segmentation from multiple labels. Inspired by the iterative half-quadratic optimization, the proposed MrPrism will combine the multi-rater confidences assignment task and calibrated segmentation task in a recurrent manner. In this recurrent process, MrPrism can learn inter-observer variability taking into account the image semantic properties, and finally converges to a self-calibrated segmentation result reflecting the inter-observer agreement. Specifically, we propose Converging Prism (ConP) and Diverging Prism (DivP) to process the two tasks iteratively. ConP learns calibrated segmentation based on the multi-rater confidence maps estimated by DivP. DivP generates multi-rater confidence maps based on the segmentation masks estimated by ConP. The experimental results show that by recurrently running ConP and DivP, the two tasks can achieve mutual improvement. The final converged segmentation result of MrPrism outperforms state-of-the-art (SOTA) strategies on a wide range of medical image segmentation tasks.
Calibrate the inter-observer segmentation uncertainty via diagnosis-first principle
Aug 05, 2022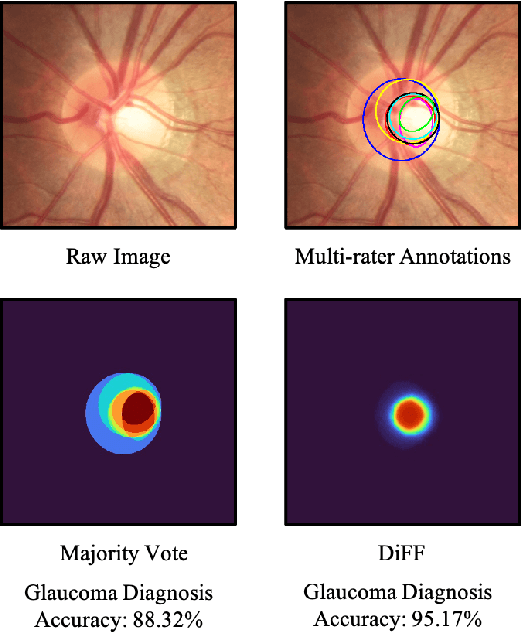
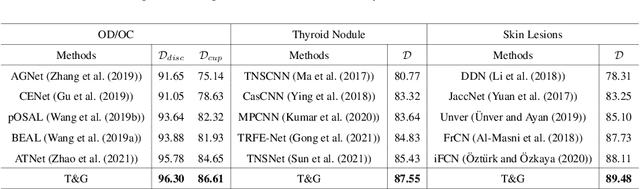
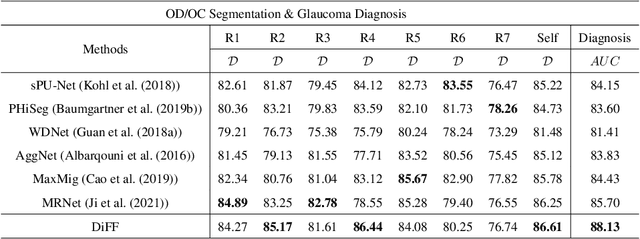
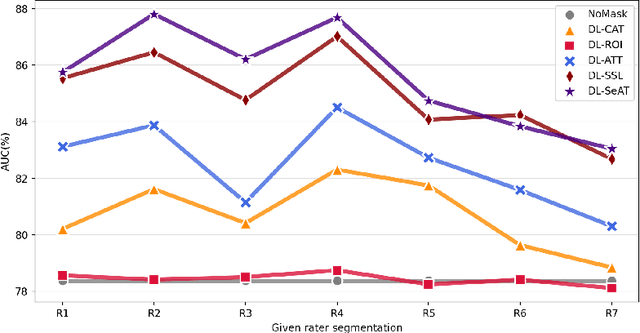
On the medical images, many of the tissues/lesions may be ambiguous. That is why the medical segmentation is typically annotated by a group of clinical experts to mitigate the personal bias. However, this clinical routine also brings new challenges to the application of machine learning algorithms. Without a definite ground-truth, it will be difficult to train and evaluate the deep learning models. When the annotations are collected from different graders, a common choice is majority vote. However such a strategy ignores the difference between the grader expertness. In this paper, we consider the task of predicting the segmentation with the calibrated inter-observer uncertainty. We note that in clinical practice, the medical image segmentation is usually used to assist the disease diagnosis. Inspired by this observation, we propose diagnosis-first principle, which is to take disease diagnosis as the criterion to calibrate the inter-observer segmentation uncertainty. Following this idea, a framework named Diagnosis First segmentation Framework (DiFF) is proposed to estimate diagnosis-first segmentation from the raw images.Specifically, DiFF will first learn to fuse the multi-rater segmentation labels to a single ground-truth which could maximize the disease diagnosis performance. We dubbed the fused ground-truth as Diagnosis First Ground-truth (DF-GT).Then, we further propose Take and Give Modelto segment DF-GT from the raw image. We verify the effectiveness of DiFF on three different medical segmentation tasks: OD/OC segmentation on fundus images, thyroid nodule segmentation on ultrasound images, and skin lesion segmentation on dermoscopic images. Experimental results show that the proposed DiFF is able to significantly facilitate the corresponding disease diagnosis, which outperforms previous state-of-the-art multi-rater learning methods.